


{kind=link}
含缺失值的重复测量资料分析在SPSS和SAS中的实现
[周倩, 张晋昕 ]
]
]
|
|


作者简介:周倩(1987-),女,湖南岳阳人,在读硕士研究生,研究方向为统计学方法研究与应用。
目的 探讨含缺失值的重复测量资料混合线性模型分析在SPSS和SAS中的实现。方法应用重复测量资料的方差分析和混合线性模型分别对抑郁治疗的资料进行分析,以治疗后抑郁量表得分为分析指标,评价不同治疗方法的效果。结果当大量个体的重复测量数据存在缺失值时,方差分析将这些个体排除在外,而混合线性模型将存在测量数据的个体全部纳入分析,二者得出不同的统计推断。结论混合线性模型可以灵活处理含有缺失值的重复测量资料,能够充分利用数据信息,结果可靠。SPSS和SAS的MIXED模块都可以实现其统计分析,且在随机缺失情况下结果一致。
Objective To discuss the realization of linear mixed model in SPSS and SAS for repeated measurements with missing values.Methods Data from a depression therapy with missing values were analyzed using GLM and MIXED procedure, so as to evaluate the therapy effect. The measurements are depression levels after treatment.Results When missing values exist, analysis with GLM procedure will exclude the subjects from further calculation, while analysis with MIXED procedure will include the subjects in further calculation. They lead to different statistical results.Conclusion MIXED extends repeated measures models in GLM to allow an unequal number of repetitions and it will still be efficient under more complex situations where data units are nested in a hierarchy. SPSS and SAS both can get efficient estimators for either balanced or unbalanced data.
重复测量资料是医学中常见的一种数据形式,是指对同一受试者的某研究变量在不同时间点上进行多次测量得到的数据。由于每个受试者重复测量值之间存在高度相关性,因此重复测量资料不满足数据独立性要求。单变量重复测量资料的方差分析对重复测量时间点数据要求满足球形对称,不满足时可以进行校正得到假设检验结果;多变量方差分析则对各时间点数据之间的方差协方差结构不作限定。这两种方法都存在一定的局限性,方差分析只适用于测量时间点固定的定量资料,且当受试者在不同时间点的测量数据存在缺失时,会将该受试者的全部信息排除后进行计算分析。另一方面,缺失值是重复测量数据很难避免的实际情况,因此在不能补充样本时,方差分析会因减小样本量而降低检验功效,且删除含有缺失的个体分析会对结论造成一定影响[ 1]。
混合效应模型包含固定效应模型和随机效应模型。固定效应是指人为设定组别的效应,比如重复测量中要比较二种药随时间变化的差异,随机抽取两组人进行药物治疗并在不同时间点进行重复测量,结论仅限于这二种药,不能推广至其他药物疗效的对比,则药物的效应就是固定效应。而随机效应则是指所纳入某水平的个体是从很多不同水平所构成的总体中随机抽取的,比如“小鼠窝别”在随机区组设计中常被作为区组因素安排,各窝小鼠就是随机抽取自众多的窝别,窝别效应就是随机效应。重复测量中的受试者是一个总体中的样本,研究是想通过比较这些样本受试者经过不同处理后重复测量的效应以便推论到其所代表的总体中去,因此在重复测量中把受试者效应设为随机效应。
SPSS和SAS对非平衡重复测量资料都设有MIXED模块,本文以一个实例对含缺失值的重复测量资料在SPSS 13.0与SAS 9.1中进行方差分析和混合线性模型分析,并附操作步骤和程序。
为研究某新治疗方法与传统方法对抑郁患者抑郁程度改善的影响,根据统一的入选标准收治100名抑郁患者,随机分为试验组(52名)和对照组(48名),试验组采用新疗法,对照组用传统疗法,统计每组患者在治疗前和治疗后2个月、4个月、6个月和8个月进行抑郁量表得分,结果见 表1。问新疗法是否比传统疗法更有效?
| 表1 两种疗法治疗抑郁患者不同时间的得分* |
(1)该资料为重复测量设计,采用重复测量资料的方差分析进行效应分析。
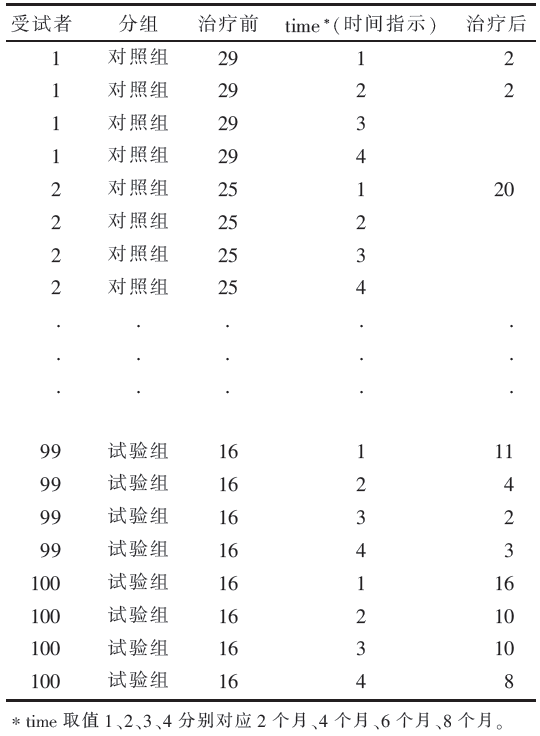
可以看到每位受试者在治疗前都有得分记录,但是治疗后的数据存在缺失,统计发现只有25名对照组和27名试验组的受试者有治疗后4次得分的完整数据,其他患者都存在不同程度的缺失值,其中3名患者只有治疗前的得分。重复测量资料方差分析只能对完整数据(也称平衡数据)进行计算,因此虽然有100名患者的资料,分析时只能用到52名患者的资料。
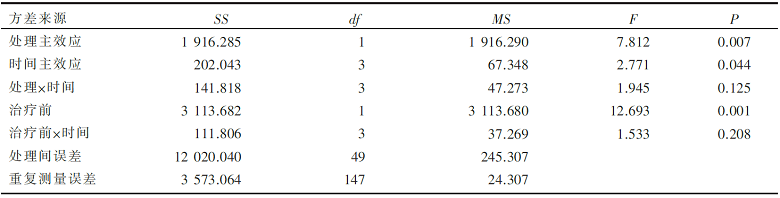
本分析将治疗前数据作为协变量,重复测量资料方差分析计算结果见 表2。该资料满足球形检验(Mauchly's W=0.933, P=0.652)。
| 表2 重复测量资料方差分析表 |
可见处理和时间的交互效应不存在统计学意义,处理主效应和时间主效应都存在统计学意义,即新疗法与传统疗法治疗抑郁的效果不同( P=0.007<0.01),新疗法的得分(9.88±5.70)低于传统疗法(16.86±11.06),因此认为新疗法比传统疗法有效;随着时间的增加得分降低( P=0.044<0.05);对照组在4个时间点的得分依次为20.08±11.50、17.84±12.16、15.92±12.79、13.60±11.47;试验组为10.85±6.54、10.33±6.91、9.48±8.07、8.85±6.09。
(2)非平衡重复测量资料的混合效应模型。
由于该资料有100名患者,但是重复测量方差分析无法利用含有缺失值的患者数据,因此采用前述方法无法反映数据的全面信息。下面将介绍采用混合效应模型对该资料进行分析的做法。
SPSS统计分析步骤见附录一。
| 表3 表1的混合模型分析通用格式 |
第二步:作图。
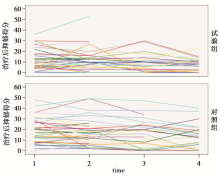
利用通用格式数据可以方便地作图观察各个受试者及分组的得分变化情况(见 图1), 图1纵轴为受试者得分,横轴为观测的4个时间点。从 图1看出两组受试者的得分大多在0~40分之间,但试验组的得分较为集中。得分随时间变化的趋势不明显。
第三步:重复测量资料的混合线性模型。
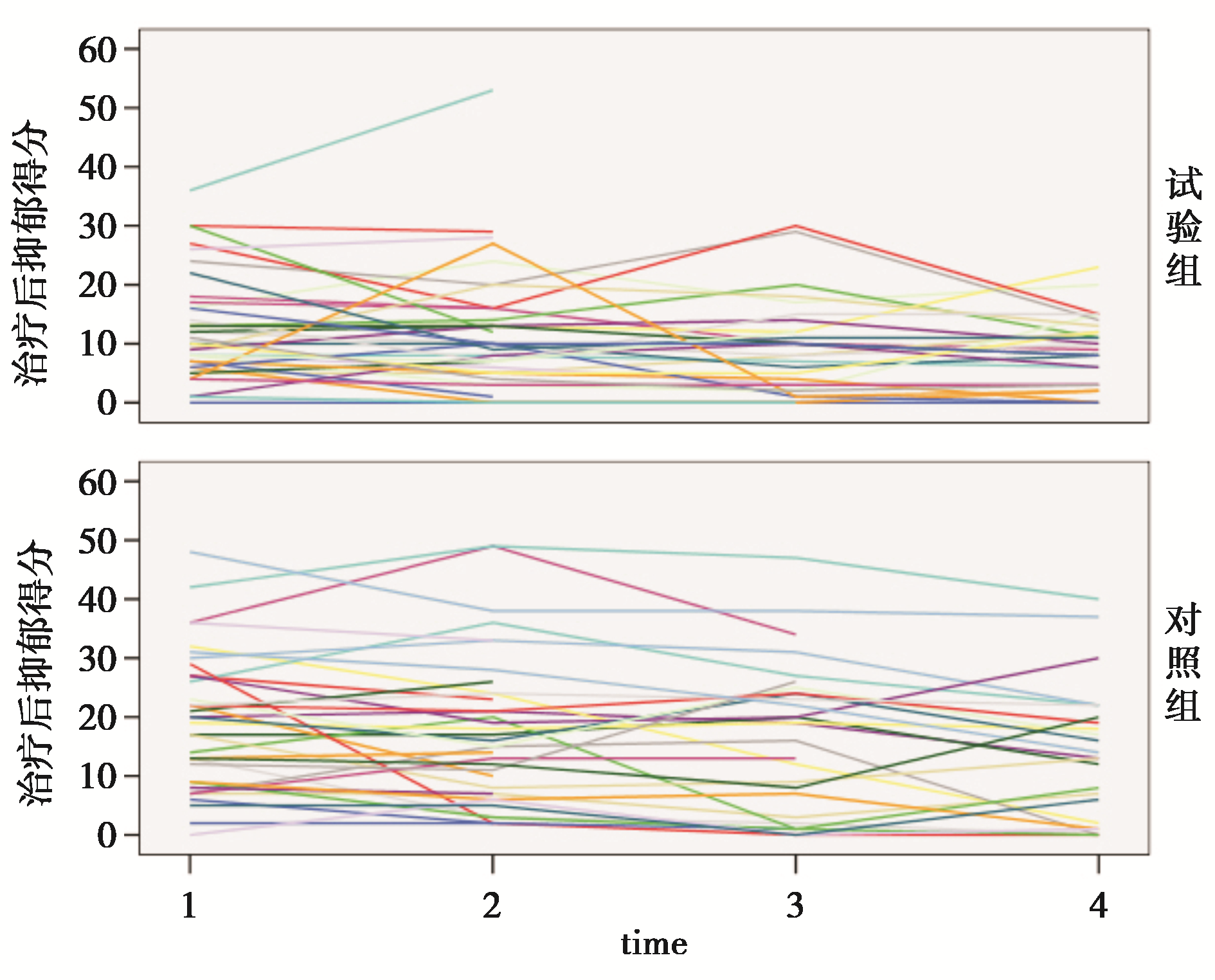 | 图1 两种治疗方法受试者得分图 |
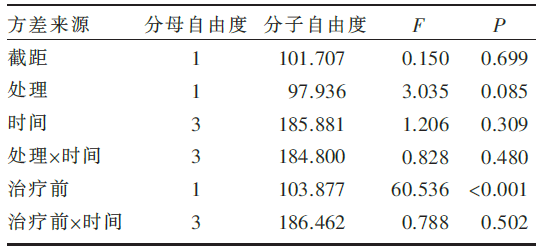
一般进行混合模型分析之前,考虑到不同变量纲的影响要对数据进行中心化处理,即将变量减去各自的均数,但本文由于没有其他测量值的协变量,且主要是为了便于与方差分析结果比较,因此不进行中心化处理。且模型设置时与方差分析保持一致,即在选择重复测量方差结构时选择复合对称结构(compound symmetry),这个结构与球形检验满足时的重复测量方差分析结构一致,在固定效应模型时也设置相同的项,并且本模型无需设置其他随机效应[ 3]。混合线性模型分析结果见 表4和 表5。
| 表4 混合线性模型固定效应 |
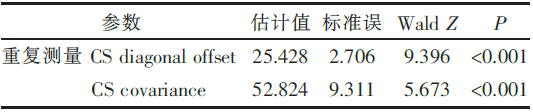
| 表5 混合线性模型方差协方差参数估计及检验 |
本模型使用了在治疗后含有至少一次得分的97名患者进行分析,所选择的重复测量结构的假设检验满足要求( 表5中的两行 P<0.05),结果收敛,说明该模型是合理的。 表4中有处理表示处理效应在治疗后第一次测量的差异是否存在统计学意义,处理×时间表示随时间变化处理效应是否存在统计学意义,即处理效应存在与否主要看处理×时间对应的 P值,分析结果表明处理效应不存在统计学意义,与方差分析结论相反。SAS软件分析的结果与SPSS结果一致,程序见附录二。
| 附录一 SPSS MIXED 操作步骤 |
重复测量资料拥有很特殊的数据结构,因此在建立混合模型时,要对重复测量的数据结构或者层次的方差协方差结构进行多个假设,选择通过检验且拟合效果较好的模型。本文旨在介绍当重复测量资料存在缺失值时用混合模型拟合数据在SPSS和SAS中的实现,由于复合对称结构满足分析要求,因此未对模型方差协方差结构进行多个选择来分析模型拟合效果,也未拟合随机截距-系数模型比较模型之间的优劣。此外,混合线性模型在拟合生长曲线时也具有明显的优势[ 4]。这些分析方法在SPSS和SAS中都可以实现,且结果基本一致,感兴趣的读者可以参阅有关文献的具体做法[ 5, 6]。
| 附录二 SAS 混合效应模型程序 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|