{kind=link}
{kind=link}
设计类型与变量类型对医学研究统计方法恰当选择的影响
[吴俊林1 , 唐雪莉1 , 陈霞1 , 戴浩然1 , 李家兵1 , 黄艳君1 , 黄国平1, 2  ]
]
]
|
|


吴俊林(1979- ),男,四川绵阳人,副编审,医学硕士,主要研究方向为临床科研统计与精神医学。
恰当的统计方法选择对医学研究结果可信度的影响显而易见,关于在医学科研中如何恰当选择统计方法的文章和著作虽然不在少数,但目前中文医学期刊中统计分析方法误用情况仍屡见不鲜。原因可能是复杂的,其中过度追求具体方法的使用而对其基本概念理解的不充分可能是误用统计方法的重要原因之一。本文将以研究设计阶段所涉及的设计类型和变量类型两个重要概念为核心探讨选择恰当统计方法需要把握的要点。旨在提高医学论文的科学性和统计学内容的编校质量。
The impact of proper statistical method selection on the credibility of medical research results is obvious. Naturally, there are many articles and works on how to properly select statistical methods in medical research. However, the misuse of statistical analysis methods in Chinese medical journals is still common. The reasons may be complex, but excessive pursuit of the use of specific methods and insufficient understanding of their basic concepts may be one of the important reasons for the misuse of statistical methods. This article will focus on the two important concepts of design types and variable types involved in the design phase, and discuss the key points to choose appropriate statistical methods. The aim is to improve the scientific and statistical quality of medical papers.
医学领域存在大量的随机现象, 比如拟研究某种药物的临床疗效, 研究实施前可预知疗效共有两种可能结果, 有效和无效, 但此时并不能预知研究实施后到底出现哪种结果。这种在事前并不能预知相同条件下每次试验的具体结果的现象称为随机现象。概率论和统计学就是研究和揭示随机现象统计规律性的科学, 统计学是以概率论为理论基础, 研究怎样以有效的方式收集、整理、分析带随机性的数据, 在此基础上对所研究的问题做出回答, 为决策提供依据[1]。可见, 在医学研究中引入统计学是必要且合理的。目前关于在医学科研中恰当选用统计方法的文章和著作并不缺乏, 并且很多文献详细介绍了统计方法使用常见错误以及正确方法[2, 3, 4], 但医学论文中统计方法误用现象仍较普遍[5, 6, 7]。其中过度追求具体方法的使用而对其基本概念和原理理解的不充分可能是错误使用统计方法的重要原因之一。由于医学统计体系庞大, 需要理解的概念较多, 本文将以试验研究设计阶段所涉及的设计类型和变量类型两个重要概念为核心探讨统计方法的恰当选择, 为医学科研人员和医学学术期刊编辑提供参考。
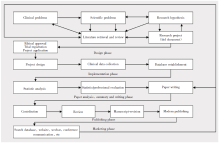
在实际工作, 常常会见到一些研究人员拿着收集好的数据找统计专家帮助分析, 而在研究设计阶段完全没有统计人员参与, 也没有做充分的统计设计思考, 假如此时数据存在严重的统计设计缺陷, 再优秀的统计学家, 再完美的统计方法也无济于事, 这无异于“ 尸体解剖仅可以得出死因而已” 。合理的科研流程应在研究设计阶段进行专业设计的同时还要引入统计设计, 它是研究方案中不可或缺的重要内容之一, 在研究与交流的其他环节也可能会涉及到统计内容, 如图1。
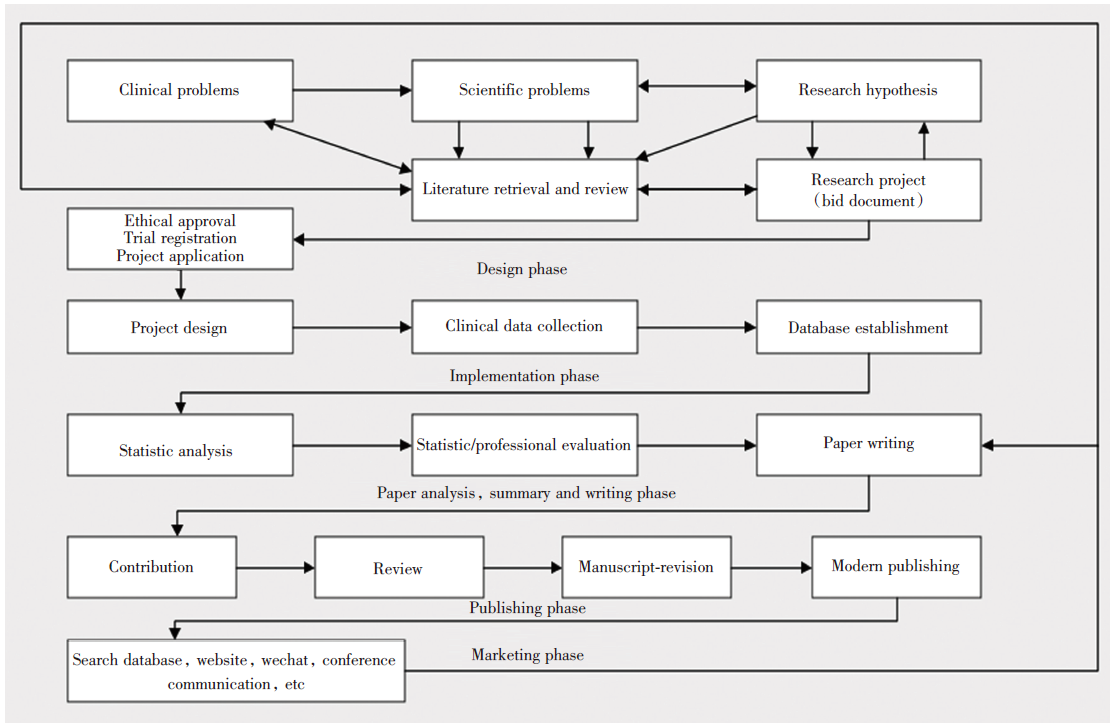 | 图1 临床研究与学术交流流程图Fig.1 Flow chart of clinical research and academic exchange |
试验研究统计设计内容包括设计类型、研究设计三要素与四原则等, 临床试验研究包括伦理审查、依从性、盲法设计等[8, 9]。其中, 设计类型与三要素中的效应指标类型(变量类型)与统计方法的选择高度相关[10, 11, 12]。
设计类型指因素及其不同水平决定的结构, 因素是研究者所考察的可能影响试验结果的各种试验条件的总称[13, 14]。比如, 某临床医生拟探讨A、B、C三种降压药对原发性高血压患者的降压效果, 此研究中药物即为一个因素, 设置三种药物, 即A药、B药和C药, 称为“ 水平” 。再如性别这一因素可以取两个值, 男和女。特别注意的是仅当取值为两个或以上时才称为因素。因素可分为试验因素(处理因素)和非试验因素(混杂因素、区组因素)[15, 16, 17, 18]。根据涉及因素的多寡将研究设计类型分为单因素试验设计和多因素试验设计, 它们分别包含多个不同的具体类型, 如配对设计、成组设计、重复测量设计、析因设计、嵌套设计、拉丁方设计等, 正确识别不同的设计类型是合理选择统计分析方法的前提之一[19, 20, 21, 22]。如某研究拟探讨帕利哌酮缓释剂与奥氮平治疗精神分裂症的效果。将120例精神分裂症患者随机分成两个药物组各60例进行治疗, 观察3个月, 于治疗前、治疗后1月末、2月末、3月末采用阳性和阴性症状量表(Positive and Negative Syndrome Scale, PANSS)测评。如果研究者多次采用成组设计一元定量资料的t检验来分析此资料, 妥否?显然不妥, 因为它既割裂了资料的整体性, 又没有考虑消除不同时间点上数据之间的内在联系对结果的影响, 如果研究者能够正确识别出此研究属于重复测量设计类型, 则应当采用具有一个重复测量的两因素设计定量资料的一元协方差分析来分析数据, 两个因素分别指药物种类和时间, 其中时间为一个重复测量因素, 治疗前PANSS的测量结果可作为协变量, 亦可作为时间的一个水平。可见, 统计方法的恰当选择与采用的试验设计类型以及正确识别出试验设计类型高度相关。
还有一类因没能正确识别设计类型而误用统计方法的典型案例, 就是把多因素的不同水平组合用“ 组别” 这个词作为变量名致使误以为是单因素多水平, 进而采用单因素多水平设计定量资料方差分析方法[23, 24]。如某研究者拟探讨人参茎叶皂苷(ginsenosides, GSS)对热损伤大鼠肝细胞糖皮质激素受体(glucocorticoid receptor, GR)的影响, 选用SD大鼠32只, 随机分为4组, 即正常对照组、GSS治疗组、热损伤模型组、热损伤模型GSS治疗组, 经过试验程序后, 测量肝细胞液GR最大结合容量。若以“ 组别” 为变量名称, 其取值分别为正常对照组、GSS治疗组、热损伤模型组、热损伤模型GSS治疗组, 则此设计类型被误判为单因素四水平设计, 采用单因素四水平设计定量资料方差分析, 这显然与设计类型不符, 采用的统计方法欠妥。仔细分析发现, 此研究至少涉及两个需要考察的因素:(1)是否为热损伤模型, 它有两个取值, 即热损伤模型和非热损伤模型; (2)是否给予GSS治疗, 它也有两个取值, 即给予GSS治疗和未给予GSS治疗。这两个因素及其水平的全面组合, 即非热损伤模型且未给予GSS治疗则为正常对照组, 非热损伤模型且给予GSS治疗为GSS治疗组, 热损伤模型且未给予GSS治疗为热损伤模型组, 热损伤模型且给予GSS治疗为热损伤模型GSS治疗组。若两因素对效应指标的影响无主次之分, 且数据满足方差分析的前提条件, 则可采用两因素析因设计定量资料的方差分析进行处理, 或影响有主次之分, 则可考虑嵌套设计定量资料的方差分析等[25, 26]。
设计类型种类较多, 它不仅与统计方法的选择有关, 还与研究目的密切相关, 熟练掌握各种设计类型的本质特征及其应用场景, 不仅是恰当选择统计方法的需要, 也是实现研究目的的需要, 当然, 恰当的统计方法的选择也是为了实现研究目的, 最终为发现科学规律, 服务人类健康。
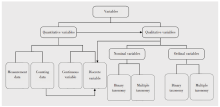
医学论文中的统计分析部分常见“ × × 计量资料采用× × 检验, ##计数资料采用##检验” 的描述, 虽然这样的表达显得有些粗糙, 但反映出选择恰当的统计方法需要对变量类型的正确识别。不同的学科将变量分为不同的类型, 如数理统计将变量分为离散变量和连续变量, 医学统计中有的分为两类有的分为三类, 如计量资料、计数资料、定量资料、定性资料, 归纳如图2。
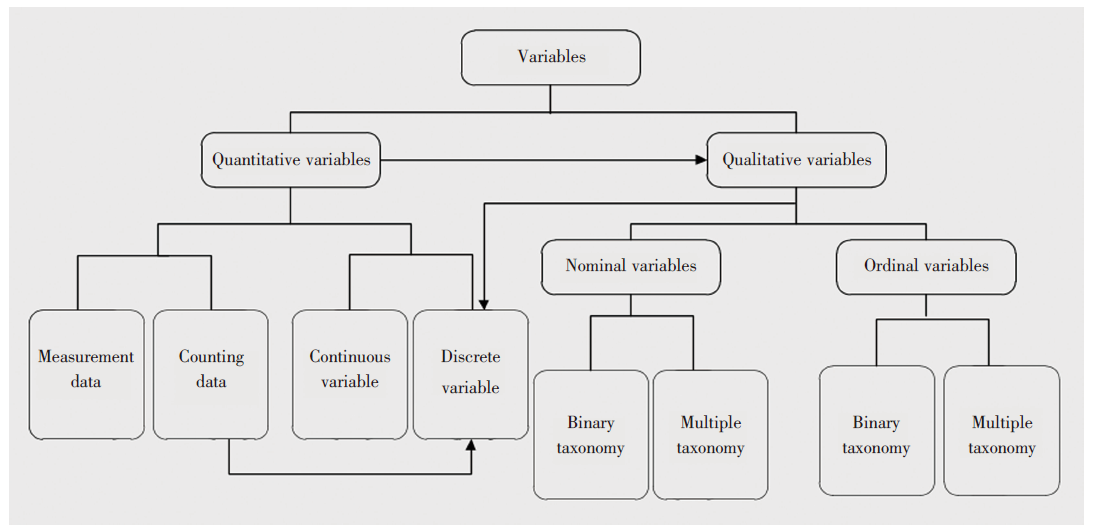 | 图2 变量分类Fig.2 Variable categories |
采用两大类四小类的分类方法来区分和识别变量类型对选择恰当的统计方法可能更有帮助, 两大类指将变量分为定量变量和定性变量, 前者进一步细分为连续变量和离散变量, 后者分为名义变量和有序变量。连续变量与离散变量的区别在于前者是连续数据, 有小数位, 后者是离散数据, 无小数位。如身高、体质量等变量虽然实际工作中都以整数形式呈现出来, 但并不代表它们不属于连续变量, 因为这是由于测量精度的原因, 如果精度足够的高, 那么任意两个数之间一定会有第三个数的存在, 可见身高、体质量属于连续变量。脉搏这类变量只能取整数数据, 属于离散变量。定性变量可分为名义变量和有序变量, 主要用于区分不同性质的事物, 且不能用具体的数值反映其结果, 但可以用数字表示定量变量的取值, 如用“ 1” 表示性别变量中男性这一取值, “ 2” 表示女性, 形式上虽是数字, 但它们并无大小之分, 不能参加四则运算。名义变量的取值可以是两个或以上, 且取值无顺序排列, 如性别变量, 它有两个取值, 血型变量, 它有A、B、O、AB四个取值。有序变量的取值存在一定的顺序, 且相邻水平之间的相差程度并不一定相等, 如疗效变量, 其取值可为痊愈、显著进步(基本痊愈)、好转、无变化、恶化五个等级。
对变量或统计数据的正确分类与统计方法的恰当选择密切相关[27, 28]。例如某研究拟探讨雌激素受体(estrogen receptor, ER)和孕激素受体(progesterone receptor, PR)在不同血管瘤发生中的意义, 采用免疫组化的方法对毛细血管瘤、海绵状血管瘤、混合型血管瘤及正常皮肤组织的ER和PR进行检测, 高倍镜下每例肿瘤区内计数500个细胞, 计算ER和PR阳性细胞百分比。如果从数据形式为“ 率” 或“ 百分比” 这一表面现象进行判断, 容易误认为它是定性资料, 随之选择χ 2检验处理数据。本例中问题的关键在于并非根据细胞测定结果的“ 阳性” 和“ 阴性” 对研究对象进行分类计数, 而是比较不同类型血管瘤及正常皮肤组织的ER和PR阳性细胞百分比的均值是否相等, 这些百分数都是每个标本测定的具体数值, 有大小之分, 应属于定量资料, 一般情况下对百分比资料宜作平方根反正弦变换, 当资料满足一定前提条件, 根据设计类型可选择单因素四水平设计定量资料的方差分析方法[29, 30]。
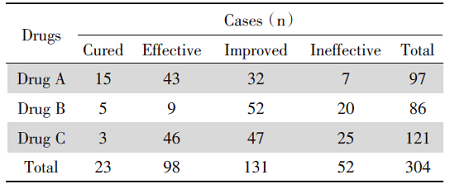
在对定性资料的分析中, 常出现对有序定性资料的顺序视而不见的现象, 导致对资料分析的不完全[31, 32]。如某研究拟分析三种药物的疗效, 数据如表1。
| 表1 三种药物疗效比较数据 Tab.1 Comparison of treatment efficacy |
表1中的数据类型比较容易识别, 它属于定性资料, 常采用一般χ 2检验, 若对其应用条件有所了解, 则会进一步检视理论频数等是否满足要求, 之后有Fisher精确检验等统计方法供选择。但如果再仔细考察数据特征, 会发现它不仅是定性资料, 而且由于疗效结果明显有等级之分, 它应属于定性资料中的多值有序变量。根据不同的研究目的, 此类资料可选择秩和检验、Ridit分析以及结果变量为多值有序变量的Logistic回归分析方法进行处理[33, 34, 35]。
虽然变量类型仅有四种, 但要对研究所获得的各种资料进行正确的分类也并非是易事, 努力弄清变量分类的种类, 把握判断资料分类的关键要点是选择恰当统计分析方法不可回避的工作。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|